Using Contextual Speller Techniques and Language Modeling for ESL Error Correction | Notes
Some notes on paper Using Contextual Speller Techniques and Language Modeling for ESL Error Correction.
使用上下文敏感的拼写检查技术和语言建模进行 ESL (English as a Second Language) 语法纠错。
Abstract
作者提出了一个模块化的系统来为非英语母语 (ESL) 写作者提供错误检测 (主要是语法错误) 和修正服务。
关注2类语法错误
- the incorrect use of determiners 冠词的错误使用
- the choice of prepositions 介词的选择
方法
- 用决策树方法 (受上下文敏感的拼写校正系统启发) 来检测语法错误并生成修正建议
- 用基于 Gigaword 语料库训练的大规模语言模型来过滤不可靠的修正建议
作者在一个非英语母语写作者产生的英文文本上做了实验,验证了系统的性能。
Introduction
背景
- 英语是国际通用语言
- 7.5亿人使用英语作为第二语言,3.75亿人母语是英语 (Crystal 1997)
- 74%的英文写作是由非英语母语者写的
- 对于非英语母语的人来说,现在的英文写作校正工具都很辣鸡,因为非英语母语者和英语母语者会犯的错误的侧重点不同,而校正工具大多是为母语英语者设计的
自动写作校正工具的挑战
- 语法错误通常出现在一个语义维度 (语义上下文?) 中,很难对它提出一个单一的修正建议
- 比如定冠词和不定冠词的选择很大程度上取决于文本上下文和世界知识
作者认为校正工具发展的趋势是:对语法错误提供一系列修正建议和真实例子,然后让用户自己去选择一个最合理的建议。
Targeted Error Types
8类语法错误 (斜体为文章关注的语法错误):
- Preposition presence and choice: In the other hand, … (On the other hand …) 介词的存在和选择
- Definite and indefinite determiner presence and choice: I am teacher… (am a teacher) 定冠词和不定冠词的存在和用法
- Gerund/infinitive confusion: I am interesting in this book. (interested in) 动名词和不定式 混淆
- Auxiliary verb presence and choice: My teacher does is a good teacher (my teacher is…) 助动词的存在和用法
- Over-regularized verb inflection: I writed a letter (wrote) 动词变形
- Adjective/noun confusion: This is a China book (Chinese book) 形容词和名词 混淆
- Word order (adjective sequences and nominal compounds): I am a student of university (university student) 词的顺序(形容词序列与名词性复合词)
- Noun pluralization: They have many knowledges (much knowledge) 名词的复数形式
一些对非英语母语语料库中语法错误的调查
- NICT Japanese Learners of English (JLE) corpus (Lzumi et al. 2004)
- 26.6% 冠词相关
- 10% 介词相关
- 口语的原文
- Chinese Learners of English Corpus (CLEC, Gui and Yang 2003)
- 粗劣的不连贯的错误标记 (error tagging),导致分离2类错误很难
- ~10% 冠词相关
- ~5% 介词相关
System Description
系统由3部分组成
- Suggestion Provider (SP)
- 包含处理上述2类错误的模块
- 预处理:分词,词性标注
- 使用了机器学习技术 (分类) 和启发式算法
- 动名词不定式混淆 和 助动词的存在和用法 - 单分类器
- 介词和冠词模块 - 两个分类器,一个判断介词应不应该存在,一个判断介词的选用
- Language Model (LM)
- SP 中给出的所有建议都会传到 LM 中
- if (一个修正建议的语言模型分数 > 原句),该建议进入候选集合
- 启发式阈值是基于类别概率的线性组合,类别概率由 SP 中分类器和语言模型分数决定
- Example Provider (EP)
- 到 Web 上查询包含修正建议的例句,辅助用户选择修正建议
Suggestion Provider
用于冠词和介词选择的 SP 模块是机器学习模型,在大规模的有错误标签和修正后的文本的数据集上训练。
- 训练两种分类器
- 检测介词/冠词是否应该存在 presence/absence classifier
- determiners pa (presence/absence) classifier
- preposition pa (presence/absence) classifier
- 如果应该存在,介词/冠词的选择 choice classifier
- determiners ch (choice) classifier: 类别有 a, an, the
- preposition ch (choice) classifier: 类别有 about, as, at, by, for, from, in, like, of, on, since, to, with, than, “other”
- 检测介词/冠词是否应该存在 presence/absence classifier
- 训练集
- English Encarta encyclopedia (560k sentences)
- a random set of 1M sentences from a Reuters news data set
- 策略
- 和上下文敏感的拼写校正器类似
- 冠词/介词的潜在插入点由词性标记的序列启发式地决定
- 对于每个冠词/介词的可能插入点,在左右各6个 token 大小的窗口内提取上下文特征,包括窗口内的每个词项抽取其相对位置、字符串和词性标记
- 基于上述特征,训练了一个分类器来做冠词选择和介词选择
- 实验中,决策树总体上比线性 SVM 表现更好,训练和参数优化上效率更高
- 使用 WinMine toolkit 训练决策树分类器
- 决策树的叶子节点中值最高的介词/冠词作为suggestion
- 如果有其他类别值的概率高于启发式确定的阈值,则这些类也在候选建议中
栗子
一个语法错误:I am teacher from Korea.
(1) 首先对句子进行分词,词性标注
0/I/PRP 1/am/VBP 2/teacher/NN 3/from/IN 4/Korea/NNP 5/./.
(2) 根据词性标记的序列和名词的大写,启发式算法认为有一个名词短语 (teacher) 前可能有一个冠词,对于这个可能的冠词位置,pa classifier 基于词性标记的特征向量和上下文计算冠词的存在概率
P(article + teacher) = 0.54
(3) ch classifier 计算不同冠词出现在该位置的概率
p(the) = 0.04
p(a/an) = 0.96 概率更高,选择 a/an 作为冠词
(4) 生成修正建议 I am teacher from Korea. -> I am a teacher from Korea.
Language Model
- 5-gram 模型,基于 English Gigaword corpus (LDC2005T12) 训练
- 为了避免单一的上下文信息,使用了 interpolated KN smoothing 插值 KN 平滑算法
- 词表 120K 词
- 语言模型包含
- 54M bigrams
- 338M trigrams
- 801M 4grams
- 12B 5grams
e.g.
原句:I am teacher from Korea. score = 0.19
修正建议:I am a teacher from Korea. score = 0.60
建议的 LM 分数远高于原句的,建议被提供给用户。
Example Provider
通常情况下,SP 会给出多个修正建议,有时候用户不知道选择哪个。这时,用户可以使用 EP 来进行 Web 查询,得到一些包含建议的例句,从而做出选择。
- 使用搜索引擎检索 web 中包含了 suggested correction 的例句
- 对于每个 suggestion,创建一个 query,其包含一个小的 suggested correction 的上下文窗口
- 将搜索引擎中检索得到的结果切分成句子,包含 query 字符串的句子被加到候选例句集合中
- 候选例句根据2个标准排名
- 句子长度(短句更佳,减少认知负载)
- 上下文 overlap(包含更多用户输入词的句子更佳)

Evaluation
- 自动评估:评估 native English text,基于假设英语母语文本中没有本系统面向的错误,母语文本中的介词选择作为监督类标 (supervision)
- 人工评估:评估 non-native text, 由评估人员评估系统提供的每个建议
独立 SP 模块
将原始训练集的 70% 作为训练,30% 作为测试。重新训练分类器,然后在测试集上进行测试。
testset 样本数量:
- 1578342 冠词修正
- 1828438 介词修正
对2个模型进行评估:
- pa: preposition/determiners presence/absence
- ch: preposition/determiners choice
综合准确性表示为:
$\frac{acc(pa) \ast votes(a) + acc(ch) \ast acc(pa) \ast votes(p)}{total \ cases}$
- votes(a): the counts of votes for class value = absence from pa
- votes(p): counts of votes for presence from pa
- acc(pa): the accuracy of the pa classifier
- acc(ch): the accuracy of the ch classifier
冠词的选择
冠词模型的准确率:
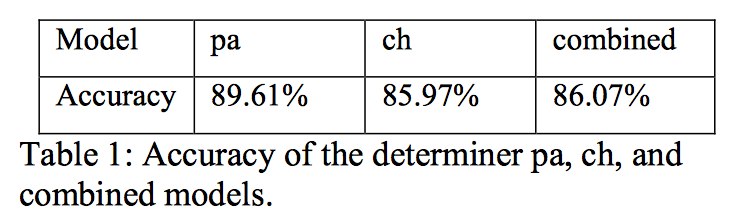
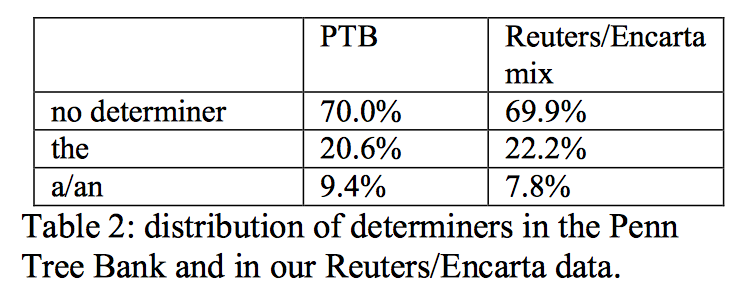
语料库中冠词的分布:
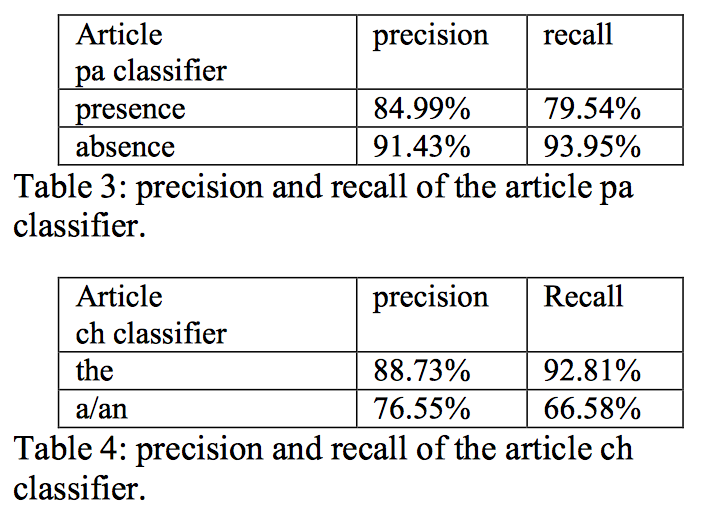
测试集上冠词分类器的准确率和召回率:
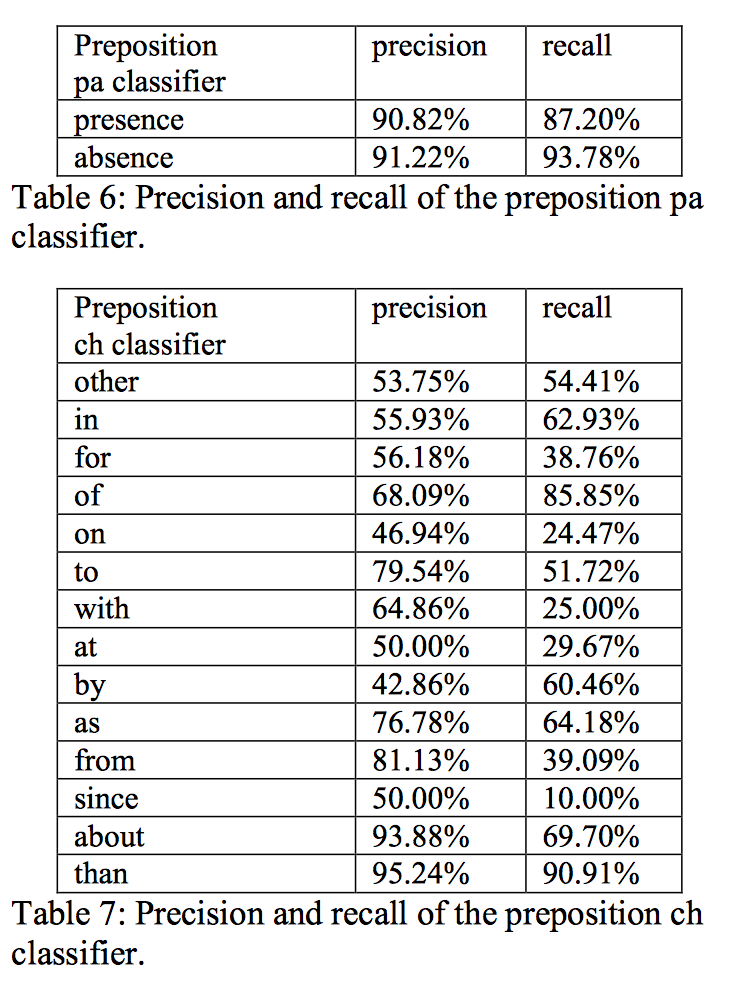
介词的选择
介词模型的准确率:
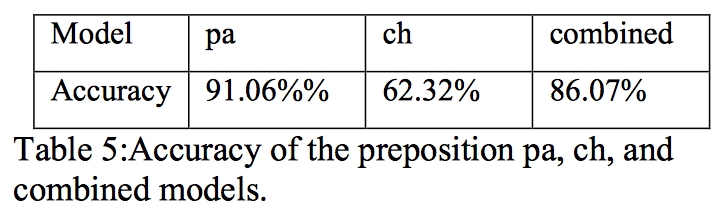
介词分类器的准确率和召回率:
语言模型的影响
语言模型用来帮助我们判断 SP 模块给出的修正建议是否靠谱。
作为过滤器的语言模型:任何修正建议的 LM 分数低于原始句子分数,那么它被过滤掉。减少了 66.8% 的介词修正和 50.7% 的冠词修正。
但 LM 本身并不能提供足够的信息,作者做了一个实验:对每个可能的介词位置生成所有的介词建议,让后用 LM 分数排名,在 Reuters 数据集上只达到了 58.36% 的准确率。
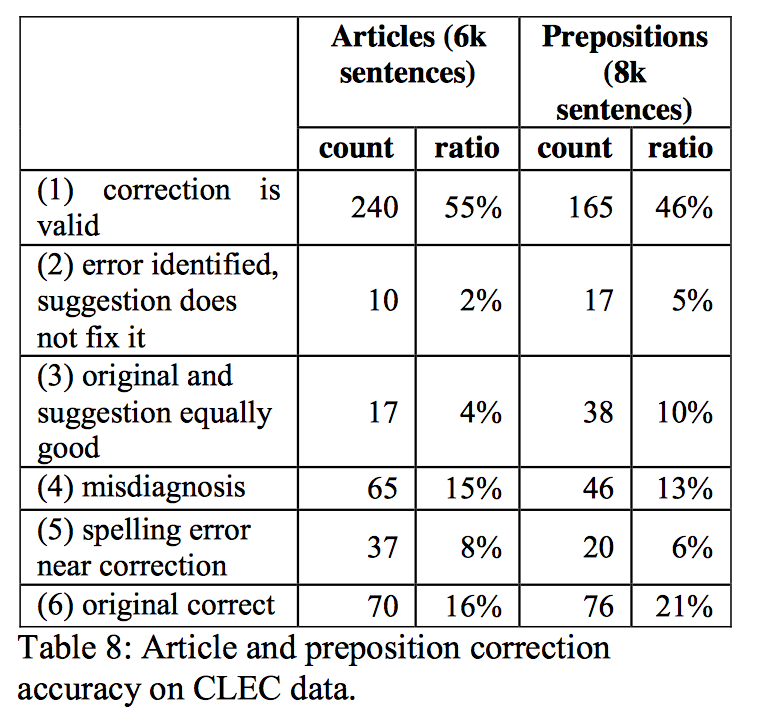
人工评估
系统将在CLEC语料库 (8k for the preposition evaluation and 6k for the determiner evaluation) 中随机抽取的样句作为输入
将评估结果分为6类:
- 更正有效的解决了问题
- 错误被正确指出,但更正没有解决错误
- 原句和更正后的句子都是正确的
- 没有正确指出错误之处
- 更正处有语法错误
- 更正错误,原句正确
在 CLEC 数据集上的 冠词/介词修正准确率:
Conclusion and Future Work
帮一个非英语母语者选择正确的冠词和介词是很有挑战的任务。
人工评估的结果是很激励人的。
目前最大的挑战是如何减少 “false flags”: 语法错误检测和修正都是错误的。
作者正在研究一个综合了 语言模型和分类器 提供的信息的排名器,使用 Web 计数作为监督数据。